If you’re looking a Helm Tutorial for Kubernetes, I’ve released a 3 hour free tutorial at YouTube.
It’s just one small part of the full 20 hour Kubernetes course that you can find at Udemy here.
If you’re looking a Helm Tutorial for Kubernetes, I’ve released a 3 hour free tutorial at YouTube.
It’s just one small part of the full 20 hour Kubernetes course that you can find at Udemy here.
(as always, sorry for the lack of posts, blah blah, mea culpa, blah).
I’ve just been reminded that “ServiceEntries” are missing from my Istio course. Many apologies to anyone who has been invonvienced by this – it was I chapter I sadly chopped out as the release deadline was looming.
The next update of the course WILL definitely cover this (alongside mirroring, authentication/authorization and a few other things). But, for now, Service Entries are pretty simple…
If you are making calls to an external service outside the cluster – it can be anything, a database or just some REST endpoint from another provider – then you can create a “ServiceEntry” which you can just think of as an external service.
Although the session on ServiceEntries was lost from the course outline, you can see that I was planning it, because the warmup exercise actually has a service entry inside it. See lines 252-267 of the 4-application-full-stack.yaml (in warmup_exercise). It looks like this:
apiVersion: networking.istio.io/v1alpha3
kind: ServiceEntry
metadata:
name: fleetman-driver-monitoring
spec:
hosts:
- somedomain.com
location: MESH_EXTERNAL
ports:
- number: 80
name: http-port
protocol: HTTP
- number: 443
name: https-port-for-tls-origination
protocol: HTTPS
resolution: DNSThis is declaring that our application is going to be calling a REST endpoint on port 80 at the address http://somedomain.com (the actual URL in the course code is a real domain, but pointing to a dummy external service I set up for the course – it’s meant to be a badly written, poorly performing service).
The advantage of this – you can now treat this service as if it were any other Istio service. So you can, for example, stop any traffic actually going to this service – this is exactly what we do in the course demo when we temporarily take the service out of action. And you will see the service appear in the monitoring such as Kiali.
It’s a very nice feature, and quite simple – just that block of yaml really.
But it should be on the course!
I got there in the end – Istio is now available at VirtualPairProgrammers.com and Udemy.com.
Udemy have started a new policy of restricting coupon codes, so the above link will give a “Best Price Match” until 9 November 2019, after that the link will work, but you’ll be subject to Udemy’s strange and complex pricing algorithm – it should still be a reasonable price though.
The aim with this course was to make Istio understandable. It’s not that hard to use really, just for some reason the docs and everything I’ve ever read about Istio seem to be riddled with unnecessary complexities and jargon. On the other hand, I think the course still goes pretty deep – we’re not shy to delve into the underlying Envoy proxies and we meet plenty of Istio gotchas along the way.
I hope this will help demystify Istio and Service Meshes in general. Istio DOES add complexity to a project, so it isn’t for every project. But the payoffs are huge, and I hope I demonstrate this.
A few topics got left behind in the rush to release – but I’ll be adding videos as free updates over time, with the first update being later in November. The main topics that missed the cut were: Mirroring (not complex but I’ve got a cracking demo); RBAC authorization (I don’t think most projects need this, although I may be wrong – but it’s still going to be good to have it in the course); External Services (no special reason why this was missing, but it’s very useful and needs to be added).
Hope to see you there!
TLDR; it looks like I might be done by October, sorry for all those who have been waiting!
I’m currently working on an Istio course – and progress has been SLOOOOOOW to say the least. 5 months in now and recording has only just begun.
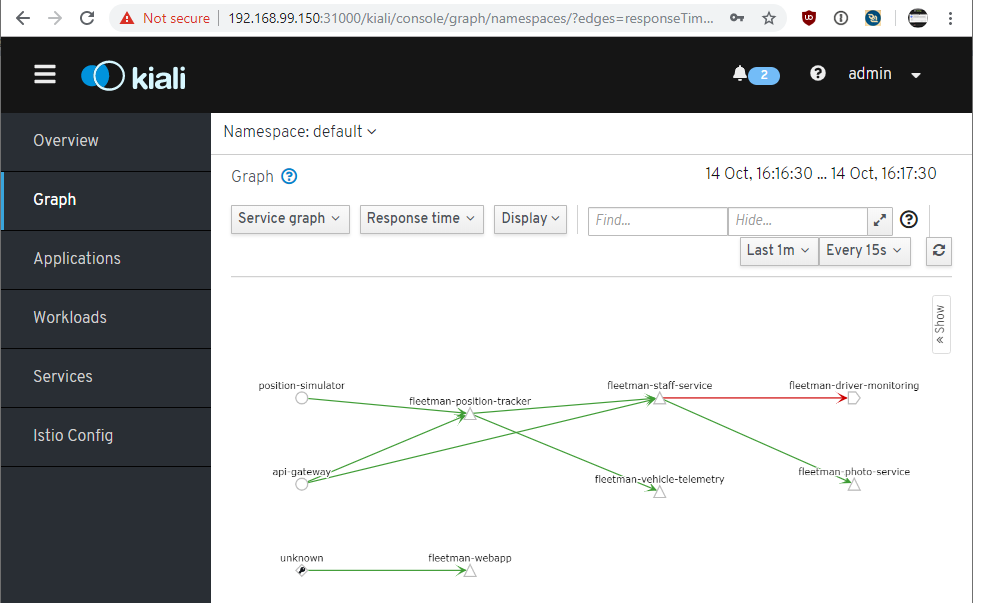
Here’s a bit of an update (and a de-compress).
Istio is probably the hardest course I’ve worked on for many years; certainly I can’t remember a tougher one.
In my company, we are currently using Istio, although we’re certainly not using it to its full potential. But just using a framework, especially one as complex as Istio, is not enough to be qualified to build a training course around it. For that, it’s necessary to take the framework apart, to understand its inner workings. To find the traps, the gotchas, the workarounds.
All of that is needed to build a good course. I’m not sure exactly how well it will turn out, but I can promise I won’t be simply running through the sample application provided on the Istio site – their abysmal “bookinfo” app just does not cut it. (Actually: the app is fine, the problem is running “kubectl apply” on a few yaml files and observing the result is not in any way insightful, but in many cases that’s all you have to go on with Istio).
Which leads me to the sample app – I’d love to build something new and fresh – honestly I’m sick of that Fleetman app, I must have spent hundreds of hours watching those trucks trundling around! I’m sure many of my viewers share the feeling! But I’ve decided to go with it, at least to offer consistency with the Kubernetes course. If I’m uncharitable about myself, I’d say I was just too lazy to write something new.
Unfortunately, Fleetman as it was on the Kubernetes course isn’t rich enough to demonstrate some of Istio’s features, so I’ve also spent many hundreds of hours upgrading that. I’m becoming more aware of my limitations as an Angular developer as I try to unpick what I did over a year ago!
In short, I’m getting there but it’s taking time. I would like to have it off my back, by the end of October at least. And then I’m taking a LOOOOOONG holiday 😉
A good question came in for the Kubernetes course:
“How to delete logs in ElasticSearch after certain period”?
A good one this. The questioner was aware that you can issue a CURL command to ElasticSearch, specifying the name of an index to delete, but this doesn’t feel very “kubernetes”. So how to do this in an elegant way – or failing that, a simple way?
Elastic do have a product that can do this, called “Curator”, but as always with Elastic’s products, I’m never sure on the licencing. Also, it seems a bit complex.
I reckon the questioner was on the right lines – with a bit of scripting and a Kubernetes cron job, we can achieve this easily.
For the answer you can jump to the end, where there’s some yaml for a cronjob, but I’m going to show my working in the next few steps…
1: The ElasticSearch API
We can indeed tell ElasticSearch to delete an index for a particular day. There’s a new index for each day. You can see your existing indexes on the Kibana “Manage Index Patterns” page.
For example, I have an index for a while back I’d like to delete called “logstash-2019.04.04”.
As ElasticSearch is running in my cluster, I’d need to exec into a container to be able to access it via curl. You’ll need a container with curl installed. (If you don’t have one, don’t worry, I’m only doing this step to illustrate the principle…in step 3 I’ll run this command from its own pod). Then I can do:
curl -XDELETE http://elasticsearch-logging.kube-system:9200/logstash-2019.04.04
Note my ElasticSearch service is called “elasticsearch-logging” and it is in the kube-system namespace, hence the DNS name.
2: Deleting logs from 90 days ago
Ok, but the requirement is to purge old logs. So how could we get rid of an index from “90 days ago”? Sounds like something we could do with a bit of shell scripting…
date -d"90 days ago" +"%Y.%m.%d"
This gives the output in just the format we need – for me today the output was “2019.03.28”. (Note: not all distributions have the version of “date” which support the fancy -d syntax. More on this shortly).
So now we’re getting somewhere – we can embed this into the API call:
curl -XDELETE http://elasticsearch-logging.kube-system:9200/logstash-`date -d"90 days ago" +"%Y.%m.%d"`
Ugly but as we say round my way, “handsome is as handsome does”. I don’t know what that means.
3: Kubernetesifying
Alright so how to apply this to Kubernetes? We can now write a CronJob which triggers this command every day. It’s common to use a minimal distro for these types of jobs, so I’m using alpine here. The drawback is that the minimal distros are just that, and alpine doesn’t come with curl OR the advanced date command. So I’ve done an ugly “apk add” in the command.
The curl package is obviously “curl” but “coreutils” gives the enhanced date command.
It would be much better to build your own image from a Dockerfile but I’ll leave that as a future enhancement. For now the following should work:
apiVersion: batch/v1beta1
kind: CronJob
metadata:
name: cron-job
spec: # CronJob
schedule: "0 0 * * *"
jobTemplate:
spec: # JOB
template:
spec: # Pod
containers:
- image: alpine
command: ["/bin/sh","-c"]
args: ["apk add curl && apk add coreutils && curl -XDELETE http://elasticsearch-logging.kube-system:9200/logstash-`date -d'90 days ago' +'%Y.%m.%d'`"]
name: logging-purger
restartPolicy: Never
backoffLimit: 2
This will run at midnight each day and delete the index from 90 days ago.
If you’re not familiar with CronJobs in Kubenetes, you’ve obviously not bought my enhanced, all-singing-and-dancing Kubernetes course! Check out a preview below and then run to here where you can get the full 20+ hour course with a discount code!
I’ve recently added a major update to the Kubernetes Microservices course. The original version of the course was a project based, hands-on approach to learning Kubernetes – which I think is by far the best way to learn. The problem with that is that it’s not always possible to fit every possible topic into a sample project – for example, Fleetman didn’t need any access control, so I didn’t bother with RBAC on the original course.
So this update fixes this! You can get the full course from Udemy or if you prefer to also get access to a curated, focused library of Java-stack related training, from VirtualPairProgrammers.com.
What’s new?
But the biggest feature request for the update – Continuous Deployment! I spent ages building a CI/CD system which you can work with – it’s functional but just basic enough so that it isn’t overwhelming.
I don’t want the blog to be just “look at me! I’ve got a new course!!” – but the problem is when I’m writing a course, 100% of my attention is on that course. For the last one, I spent more hours than I dare admit trying to work out the implementation of HashAggegration in Apache Spark. While I’m doing that, I can’t think about anything else (too much info warning: look away now: even basic operations such as eating, cleaning and basic hygiene go out of the window. Weep not for my sacrifices to the community, and buy buy buy!)
So instead of just shoving up a “new course announcement!” I’ll lead this blog post by announcing I got together with Matt for an off the cuff podcast, and it’s just released here:
Sales spiel : we’re talking a lot on that podcast about the latest release (Apache Spark). You can get it here for (as far as I now, Udemy have odd sales) the lowest possible price: https://www.udemy.com/apache-spark-for-java-developers/?couponCode=SPARKBLOG
The podcast is an odd beast, we called it “All Things Java” but it’s a misnomer. Actually the design of the podcast is that it’s supposed to be the Virtual Pair Programmers team meeting – ie something we would have to do anyway – and we release it with the minimum of editing. Maybe if we mention any specific financials we might edit that out. Otherwise, it’s warts and all. We don’t pretend to be on top of the latest developments in Java, we don’t pretend to be master business people.
So I feel that the podcast might disappoint those wanting a pure Java podcast (I really miss the old “Java Posse” podcast, we certainly couldn’t replicate what they did), but I hope it might be of interest to anyone with an interest in Java (natch), but also business, content creation and the general problems of trying to be successful in software. Maybe we’ll rename it one day, if we can be bothered.
Second course to be published at Udemy: Kubernetes Microservices.
I’ve set up a coupon code for a great deal.
Unlike the previous Docker course, this one is independent of programming language (Angular 6 used on the front end)
– although of course I can’t help dropping in a few references to Java along the way.
It’s a 12 hour hands on project: scenario – developers have pushed a set of images for a microservice system. Your mission, should you choose to accept it: define a Kubenetes workload locally, then deploy it to the cloud. Build in a level of resilience and then set up a proper ElasticSearch basic logging and monitoring system.
At the end of the course you’ll use your monitoring system to discover the developers did a pretty bad job in one of their images!
It was fun to record, hope it will be fun to watch and more importantly, a great set of real world skills for you.
A version of the course will appear in around a week at virtualpairprogrammers too.
I’ve just released my first course on Udemy. It’s a combination of the two modules I’ve previously published at VirtualPairProgrammers.
If you’re already a subscriber at VirtualPairProgrammers don’t buy the course again – but if not this course is a great way to get some real hands-on experience of Docker in a production cloud environment. I’ve set up a discount code for Udemy, follow this link for a great deal.
Kubernetes next up in a week or so!
TLDR; create a .dockerignore file to filter out directories which won’t form part of the built image.
Long version: working on the upcoming Kubernetes course, with a massive deadline looming over me [available at VirtualPairProgrammers by the end of May, Udemy soon afterwards], the last thing I need is a simple docker image build freezing up, apparently indefinitely!
A quick inspection of running processes with Procmon (I’m developing on Windows) showed a massive number of files being read and closed:
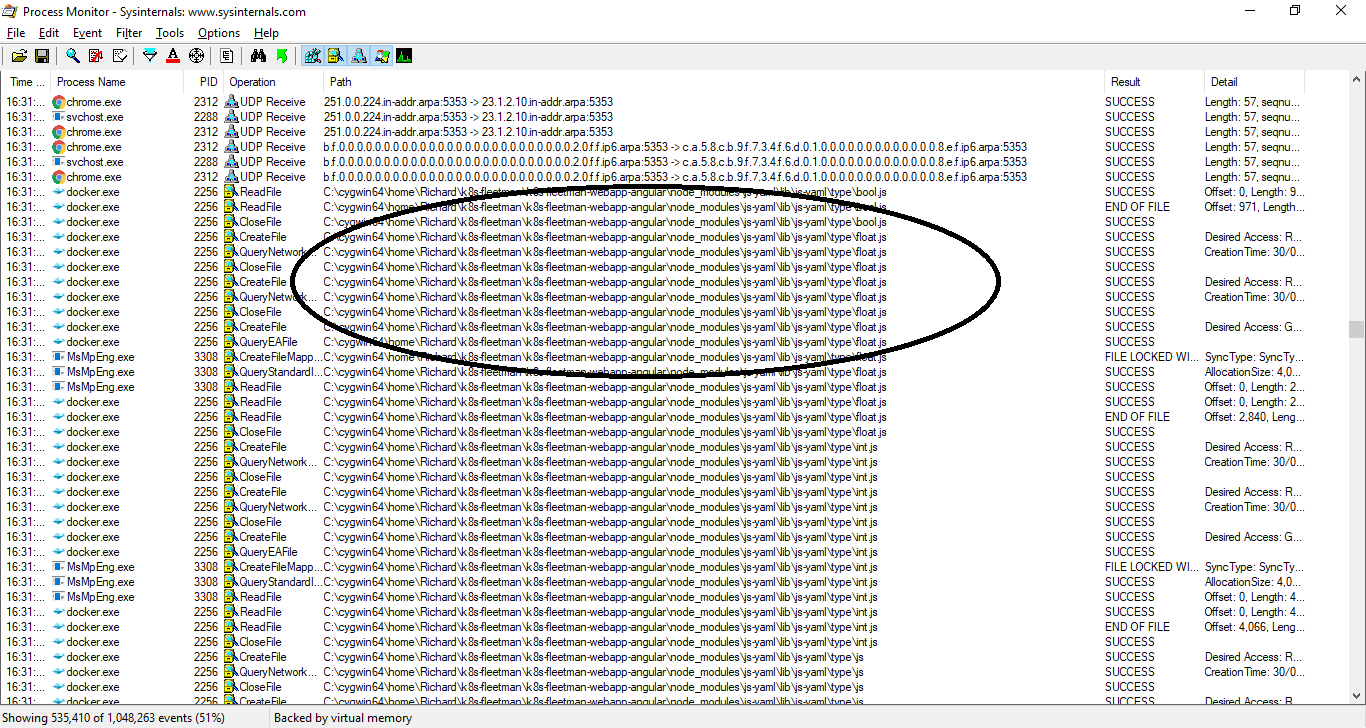
This just a small extract from the process log.
This [every file in the repository being visited] is normal behaviour of the docker image build process – I guess I’ve just been working on repositories with a relatively small number of files (Java projects). This being an Angular project, one of the folders is “/node_modules” which contains a masshoohive number of package modules – most of which aren’t actually used by the project but are there as local copies. This directory can be easily regenerated and isn’t considered part of the project’s actual source code. [edit to add, it’s the equivalent of a maven repository in Javaland. The .m2 directory is stored outside your project, so this isn’t a concern there].
Turns out, the /node-modules folder contained 33,335 files whilst the rest of the project contained just 64 files!
Routinely, we .gitingore the /node_modules folder, and of course it makes sense to ignore this directory for the purposes of Docker also.
Simply create a folder in the root of the project, .dockerignore:
$ cat .dockerignore /node_modules
Now my docker image build is taking a few seconds instead of several hours. Perhaps I might meet this deadline after all…