I’m busy working away on a new Microservices using Spring Boot course for Virtual Pair Programmers. I hope my next blog post will be a draft running order with an estimated release date: in the meantime as promised I’m going to look at how to call a Microservice.
Along the way I’ll point out how Spring Boot can help – at the same time this is helping me to decide what needs to be on the new course.
As per last week, my old monolith (which is eventually going to be broken down until nothing remains) is going to call a new Microservice, the “VAT service”. It has a single responsiblity, to return the Tax due on an amount, based on the country of residence for a customer.

It’s easy to make these things simple on a training course – in real life various governments have conspired to make VAT a living nightmare, so really this service has to deal with IP addresses, Physical Address and location of requesting bank. But that’s ok, the microservice still has a single responsibility. Don’t be afraid to build microservices which may feel trivially small – that’s part of the point (and they tend to grow anyway).
Obviously, we need to call this microservice. How?
Approach 1: The easy way – a naked REST call
Although I advised in the previous blog that you can and should consider other remoting solutions such as gRpc, let’s assume we’re going with REST. It’s kind of standard.
As you’re reading this blog, you’re probably a Spring fan, so let’s also assume that the caller (client, at present the monolith) is using Spring. So the natural choice is to go for the RestTemplate.
We’ve covered the RestTemplate extensively in our Spring Remoting course, so I won’t labour the point. But something like:
String countryRequired = "GBR";
Percentage vatRate = template.getForObject("http://localhost:8039/vat/{country}",Percentage.class,countryRequired);
Almost a no brainer. Things to consider:
- We need to get rid of the hardcoded URI – ideally we would have a service discovery solution as part of our architecture. Itouched on this briefly last time, but Spring Boot has a plugin which wraps up the very easy to use Eureka, which was originally
built by Netflix. Although we use Kubernetes on our live site, I’ve decided that as Eureka is so tightly integrated with Boot, it
would be a shame not to cover it. So it’s going to be on the course!
- What happens if the VAT service is down? In a Microservice architecture, you must assume that at any one time, at least one
service is likely to be unavailable. Again, further Netflix components can help, and Spring can easily integrate with Ribbon (for load balancing) and Hystrix (for Circuit breaking – more on circuit breaking in a future blog post).
Together, these two sub-frameworks can lead to a very robust architecture. I’ll be making sure that our practical work on the course explores this in full.
Approach 2: using Feign to hide the remote call
Naked rest calls are all well and good – they’re simple – but I always get the feeling that I’m breaking an abstraction. I
don’t want to feel that I’m making a Http call(*) – as a business programmer, I’m calling a service and that’s how I want to think
in the code.
(*) Note: this will make some people angry. When working on distributed systems, we must never forget the Fallacies of Distributed Computing, in this case we must never forget that we are making a remote call and it can 1) fail and 2) take a long time. Many argue that by abstracting away the remote call, we are making it easy to forget this. It’s a good point which I accept and remain mindful of.
It would be great if I could call this service using idiomatic Java/Spring/Dependency Injection, a little like this:
public class BlahBlah
{
@Autowired
private VatService remoteVatService;
public void billCustomerOrWhatever( .. params .., String countryOfOrigin)
{
Percentage vatRate = remoteVatService.findVatRateForCountry(countryOfOrigin);
// blah blah blah
}
}
And we can! Yet another element of the Spring Cloud library is called “Feign“. I admit I didn’t know about this until recently (how do you keep up with Spring when it expands faster than my brain cells can work?) – I’ll be covering it on the course but it’s as simple as declaring the Interface in the usual Java way:
public interface VatService
{
public Percentage findVatRateForCountry(String country);
}
Rather like with Spring Data JPA (which I covered in the Spring Boot course), you do NOT implement this interface – it’s done for you via a generated runtime Proxy.
You do need to add a few annotations, so that the generation knows how to translate the Java into REST calls. Cleverly, we use standard SpringMVC annotations (of course usually these annotations are used when defining the server side – this is the first I can think of where I’ve used the annotations client side!)
@FeignClient("/vat")
public interface VatService
{
@RequestMapping(method=RequestMethod.GET,value="/{country}")
public Percentage findVatRateForCountry(@PathVariable("country") String country);
}
Beautifully, this all integrates with the Ribbon load balancer that I mentioned above, so if we’ve replicated the service on multiple nodes, it’s easy to provide failover and fallback behaviour.
Approach 3: Use Messages
The call to the VAT service probably needs to be synchronous, because we absolutely need to know the answer before the user can proceed with what they’re doing. But in many cases, a message driven solution is another way of building a robust system.
A working example is that our system needs to record viewing figures. Every time a video is watched by a subscriber on our site, we record this as a “watch”. We use the data to decide which courses are a hit, and we can also identify unusual viewing patterns (this is a polite way of saying “we can find out who is using site scrapers”).
If we have a microservice which is responsible solely for recording viewing, we can of course use REST to log the view.
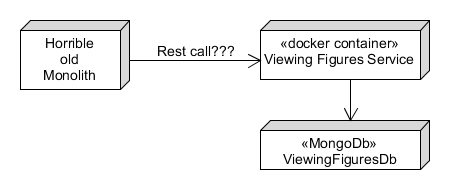
Notice the new service has its own private database, as described in part 1. We’ve chosen MongoDb – it has its detractors, but it will work well for this type of data. We can easily store large blocks of the viewing figures in memory, so it’s going to be easy to do fast calculations and aggregations. When this was handled by the monolith in MySQL, doing even basic calculations was grinding the whole system to a halt. One of the joys of microservices is we can make these decisions without too much agony – if it doesn’t work out, we can tear down the whole microservice and replace it with a different solution. I call this “ephemerality” but it’s a pompous word so it will never catch on.
This call doesn’t need to be synchronous – the video can safely play even if we haven’t yet logged the viewing. There are ways of
making asynchronous REST requests (Spring features an @Asynch annotation which starts a new thread – I’ve never covered this on any course, but I will maybe get around to that someday).
But this is a great use for messages. Instead of making a call to the service, we could just fire off a message to a queue. We don’t care who consumes the message – we just know we’ve logged that message.
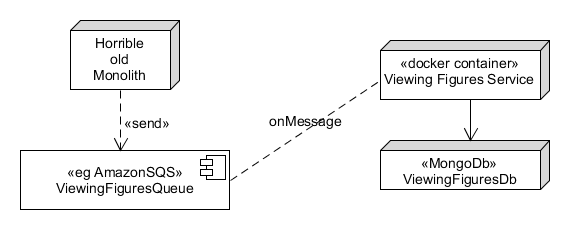
We would then just make the ViewingFigures service either respond to messages on that queue – or, even better, we could use a Topic instead of a Queue. With a Topic, multiple consumers can register an interest. So, in the future, if new services are built which are also interested in the EVENT that a video has been watched, well, they can subscribe to that topic as well.
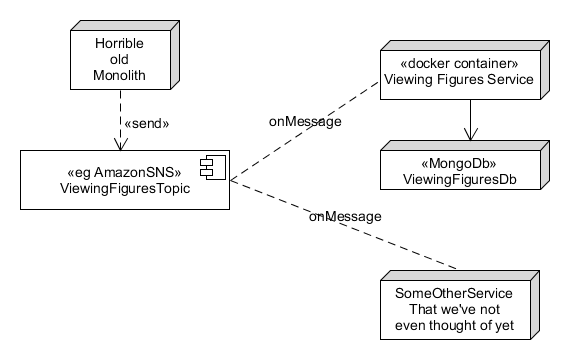
A Topic has multiple subscribers which can be added over time. Note that on AWS this is implemented using the SNS, Simple Notification Service
This gains us the robustness that we desired above, without the need for extra plumbing such as circuit breakers and load balancers. If the viewing figures service goes down, it’s no problem to the monolith as it isn’t calling it – it’s just sending a
message to a queue or topic. The queue will start to backlog the messages until the service comes back up again, and then the service can catch up on its work.
Things to think about: it is essential to ensure the queue has an extremely high uptime. With a few mouse clicks (* see footnote), Amazon SQS
automatically provisions a queue which is transparently duplicated across multiple Availability Zones (data centers). You can’t assume it will NEVER go down and you must code for this on the calling side. In this case, I would log the exception and carry on, it’s no disaster if we miss some viewing records.
Although we’ve covered messaging in standard JavaEE (and we have a course covering this on WildFly releasing soon), for some reason we’ve never covered messaging for Spring. So that’s going to go on the new course as well!
As always, I’m sorry for the long blog post, I didn’t have time to write a shorter one – I’m busy working on the new course!
(* footnote) Edit to add: Ahem, I meant, of course – “with a simple script, under source control, using a tool such as Puppet, Chef or Ansible”. That needs to be a course too!




